The OpenEMPI Matching Engine
Turn duplicate records into one source of truth.
OpenEMPI is an enterprise entity-resolution engine that deduplicates and links records at scale. Deterministic, probabilistic, and artificial intelligence-based matching in one configurable pipeline — built as a Master Patient Index for healthcare, proven anywhere identity matters.
5–20%
Duplicate-record rate in a typical EMR — the gap OpenEMPI closes.
3 paradigms
Deterministic, probabilistic, and artificial intelligence-based matching in a single engine.
Any record
Patients, providers, customers, or any entity you define.
OpenEMPI in plain terms
The product is built for organizations that need one reliable identity view from many imperfect data sources.
What is OpenEMPI?
OpenEMPI is commercial entity-resolution and record-deduplication software that links duplicate records into trusted master records.
Who uses OpenEMPI?
Healthcare teams use it as a Master Patient Index, while data and integration teams use the same engine for provider, customer, business, and registry data.
Is OpenEMPI only for healthcare?
No. Healthcare is the flagship use case, but the matching engine works with any record type whose attributes can be compared and resolved.
What business problem does OpenEMPI solve?
It reduces duplicate records, improves identity confidence, and gives downstream systems a cleaner source of truth for operations, analytics, and integration.
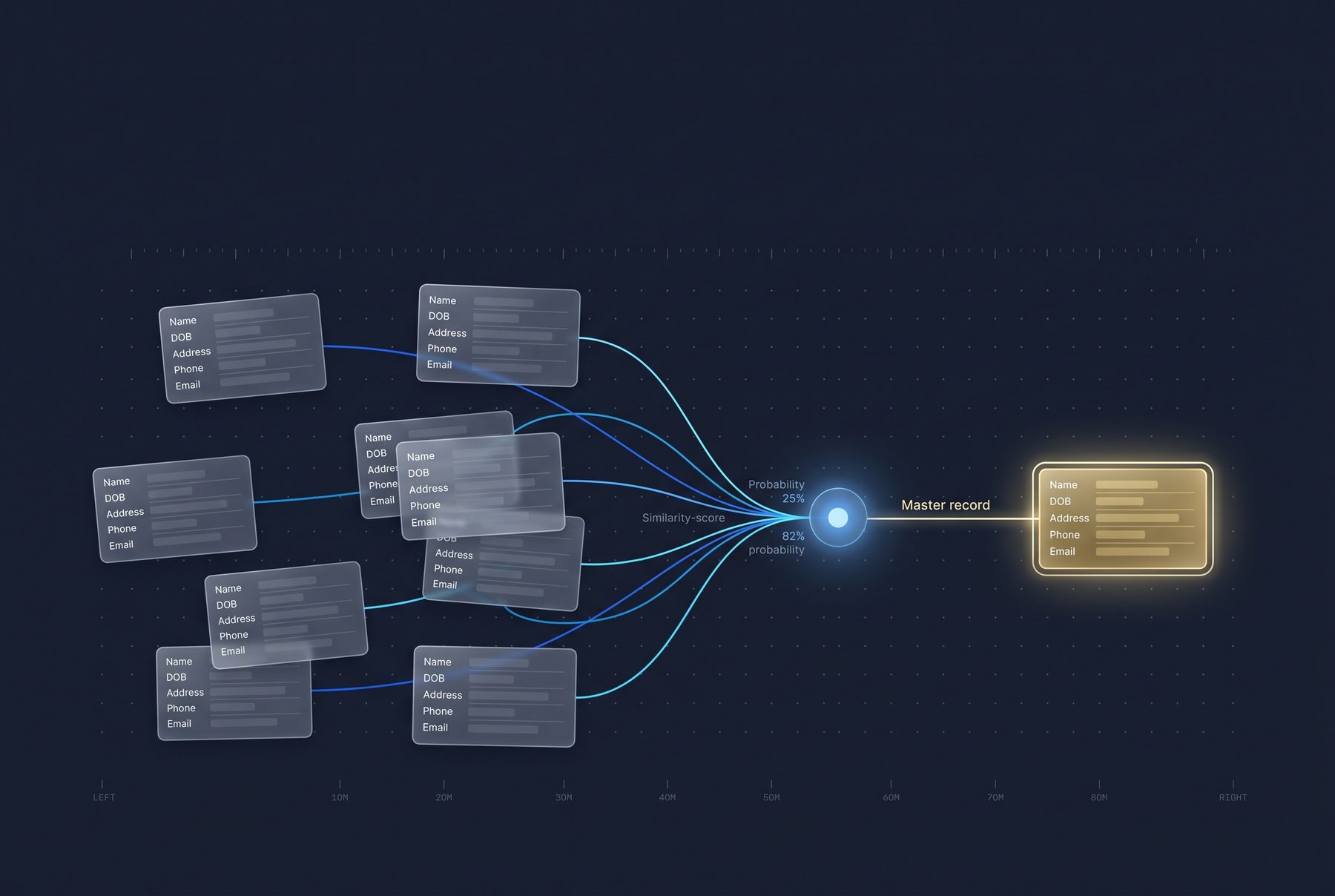
How identity gets resolved
Every record runs through the same transparent pipeline. Each stage is configurable, so you can tune accuracy to your data quality and review tolerance.
Standardize
Names, dates, phones, and addresses are parsed and normalized so records compare on equal footing.
Block
Candidate pairs are grouped in clusters based on similarity to keep matching fast at scale even in instances with tens of millions of records.
Score
Field-level distance metrics feed Probabilistic, Deterministic, and Artificial Intelligence models to score every pair.
Resolve
High-confidence matches are grouped into a single golden record; uncertain pairs route to review.
An engine built for matching at scale
Cutting-edge algorithms, an extensible architecture, and a data model you define — the same flexibility across every component.
Configurable matching algorithms
Run deterministic, probabilistic, and artificial intelligence-based matching in one pipeline. Tune the strategy and distance metrics to your data instead of bending your data to the tool.
- Probabilistic linkage
- Artificial intelligence models
- Jaro–Winkler · Levenshtein · Soundex · Double Metaphone

Human-in-the-loop stewardship
Uncertain matches surface in a review queue with confidence scores, merge/reject controls, and a full audit trail — so data stewards stay in control of every merge.
- Confidence-scored candidate pairs
- Merge / reject with full audit logging
- Real-time & batch processing modes
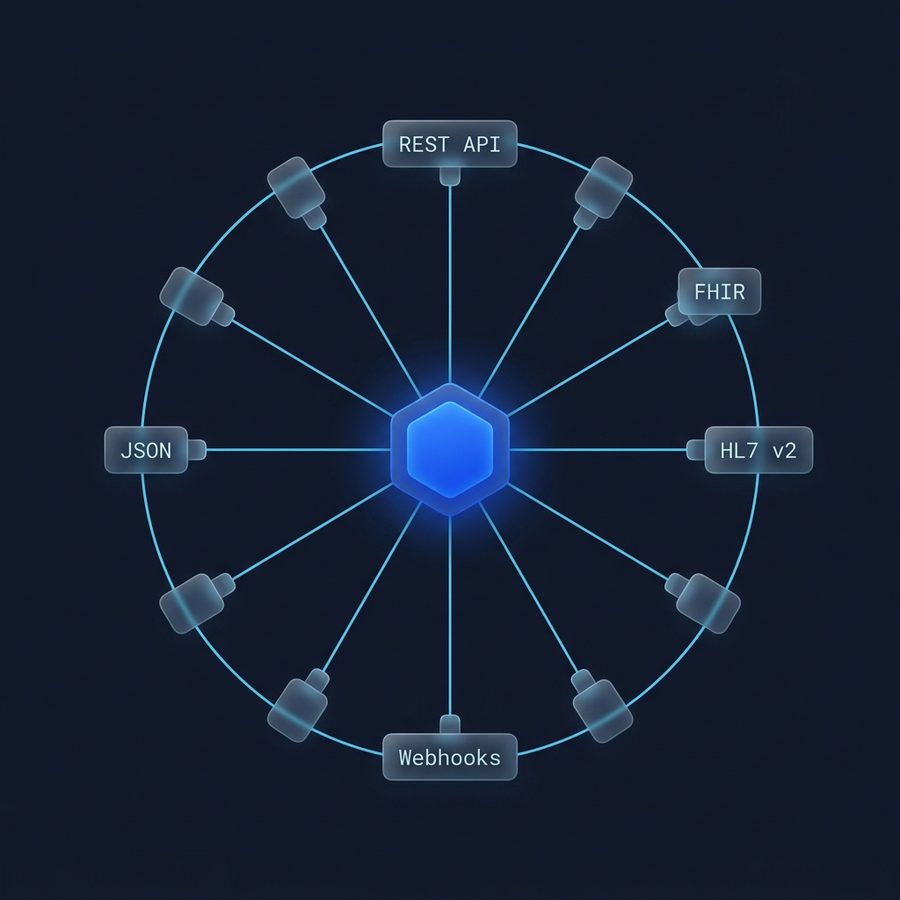
Integrates with your stack
OpenEMPI lives inside your architecture, not in place of it. A REST API and webhooks connect it to your data lakes, warehouses, and operational systems.
- RESTful API & webhooks
- HL7 v2/v3 & FHIR for healthcare
- Customizable, domain-agnostic data model
Deduplication for every domain
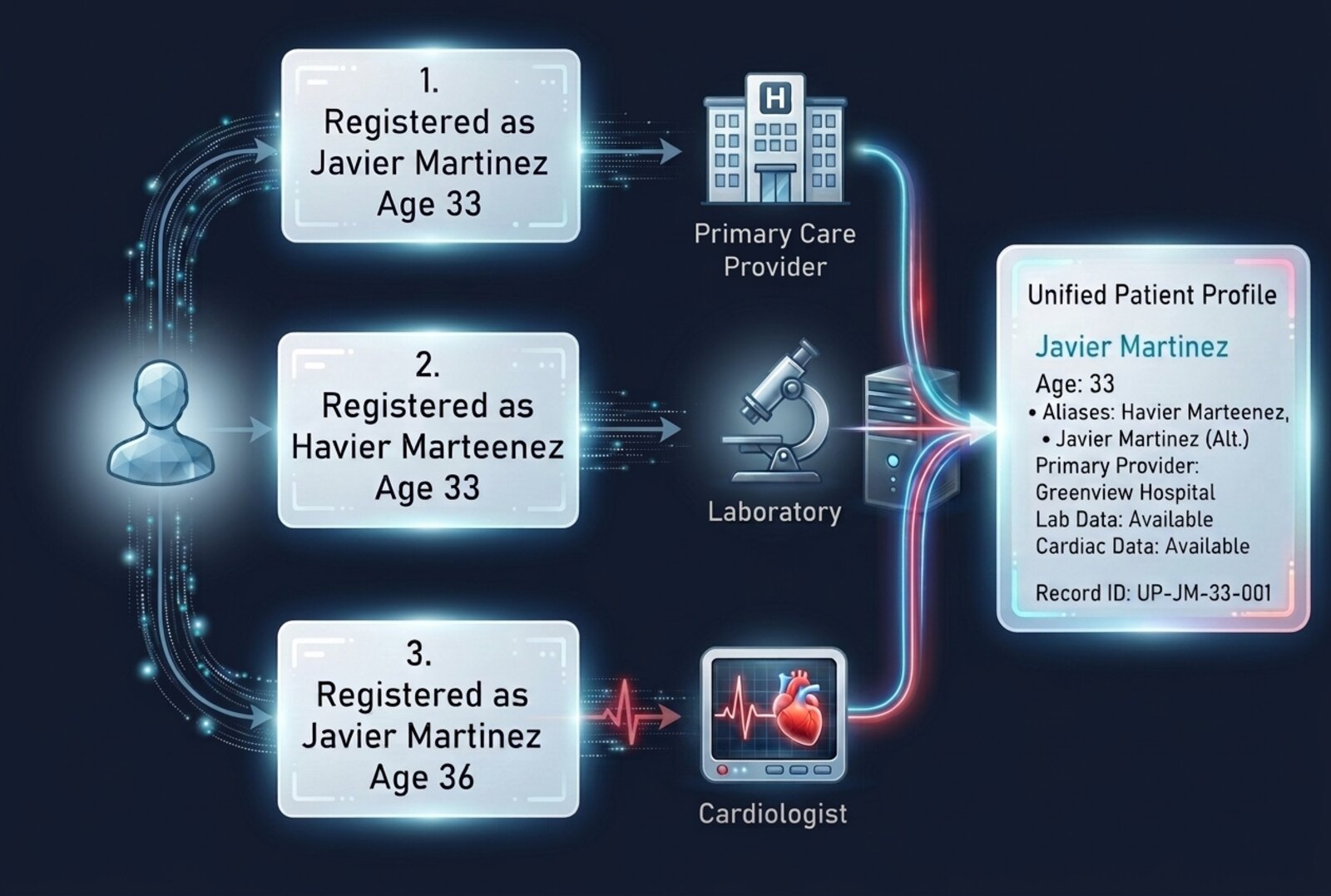
OpenEMPI began as a Master Patient Index. The same engine resolves identity wherever duplicate records undermine trust in your data.
Master Patient Index
FlagshipThe flagship use case. Resolve duplicate patient records — which run 5–20% in a typical EMR — into one accurate identity across every system of care.
Provider & facility directories
Maintain a clean, authoritative registry of providers and facilities, free of duplicate and conflicting entries.
Customer 360
Unify customer records scattered across CRMs, billing, and support into a single trusted profile.
Business & entity listings
Deduplicate suppliers, accounts, and business listings to keep master data reliable across the enterprise.
For executives
Cut the operational cost and compliance risk of duplicate records. OpenEMPI gives the enterprise a single, reliable source of truth — backed by commercial support.
- Rapid time-to-value
- Commercial support & SLAs
- Improved quality of care & cost savings
- Scalable licensing
For engineers
A high-performance matching engine with runtime-configurable algorithms and an extensible architecture. Integrate via REST or webhooks into your existing data pipeline.
- Probabilistic & ML matching
- RESTful API & webhooks
- High-throughput, horizontally scalable
- Customizable data model
Ready to deduplicate with confidence?
Tell us about your data and the records you need to resolve. We'll show you how OpenEMPI fits your stack.